코루틴 플로우 내부 살펴보기 1
Coroutine flow under the hood (cold flow)

Korean [English]
(목차로 돌아가기)
요즘 많은 안드로이드 프로젝트들이 Java -> Kotlin 전환을 하면서 데이터 스트림 처리에 RxJava/Kotlin 을 사용하던 부분들이 Coroutine Flow 로 많이 전환되고 있습니다. RX 에 비해서 내장 오퍼레이터 및 스트림 윈도우 컨트롤 등의 자체 제공되는 기능이 많지 않지만 그 덕에 더 가볍게 사용할 수 있고, 오퍼레이터가 중단함수를 지원함으로써 더 직관적으로 스트림 체인을 구성할 수 있어 많이 이용되고 있습니다.
(물론 안드로이드 JetPack 의 많은 라이브러리들이 중단함수를 지원하고 있고, 이를 이용할 수 있는 것은 덤 입니다. 😀)
이번에는 Flow 가 내부적으로 어떻게 동작 하는지 살펴보고자 합니다. 먼저 대략적인 다이어그램을 통해서 Flow 세상의 구성 요소들에 대해서 살펴봅시다.
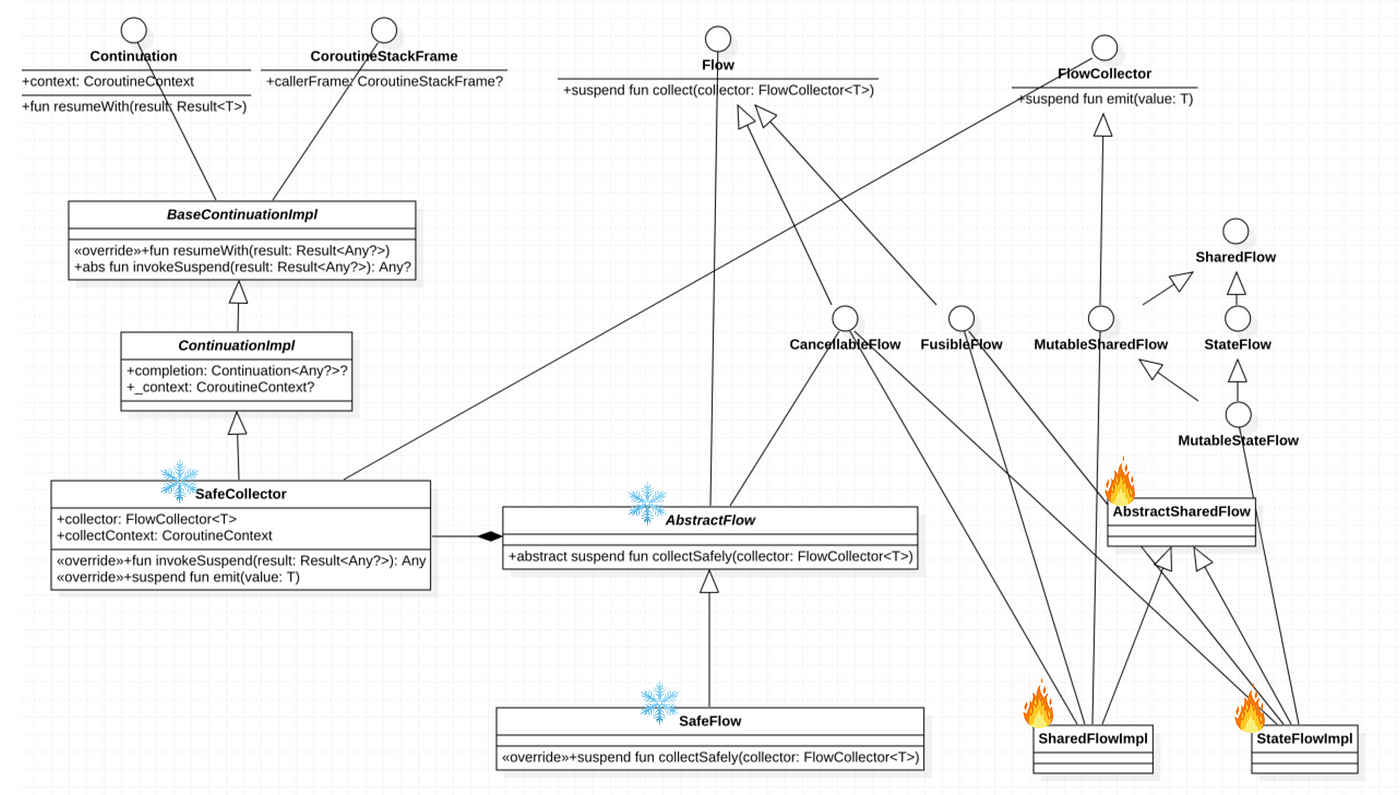
위 다이어그램은 이번 설명에 불필요한 함수등은 생략하고 관계 위주로 작성되었습니다. 그래도 다소 복잡해 보일 수 있겠지만 우리가 이번에 주로 살펴볼 부분은 플로우 자체에 대한 부분과 Cold Stream 인 콜드 플로우 (가운데 얼음 표기 부분)이며, 콜드 플로우를 Hot Stream 으로 변환한 StateFlow 와 SharedFlow 에 대해서는 이어지는 주제로 다룰 예정이므로 살펴볼 부분이 생각보다 많지는 않습니다. 😅
Cold Stream : 스트림의 구독자마다 개별 스트림이 생성/시작되어 데이터를 전달하며 그렇기에 스트림 생성 후 구독하지 않으면 어떤 연산도 발생하지 않습니다.
Hot Stream : 스트림이 생성되면 바로 연산이 시작되고 데이터를 전달하며 다수의 구독자가 동일한 스트림에서 데이터를 전달 받을 수 있습니다.
(스트림을 Lazy 하게 시작한다거나 구독자가 이전에 발생한 일정량의 데이터를 전달 받게 하는 등의 설정이 가능합니다.)
다이어그램 제일 왼쪽 위를 살펴보면 Flow 는 collect 라는 중단함수를 하나 갖는 인터페이스 라는 것을 알 수 있습니다. 우리가 flow { } 빌더를 이용하거나 MutableStateFlow, MutableSharedFlow 등의 생성자를 이용하여 Flow를 생성하면 이 Flow 인터페이스를 구현하는 적절한 형태의 Flow 가 생성되며, 생성 된 Flow 에 collect 중단 함수를 호출하면서 FlowCollector<T> 를 전달하면 해당 Flow 를 시작시키고 FlowCollector의 emit() 함수를 통해 데이터를 전달 받을 수 있습니다.
하지만 생각해보면 우리가 Flow 를 이용할 때에 collect() 중단함수 호출 시 FlowCollector 를 생성하여 전달한 기억은 없을 것 입니다. 우리는 보통 위 코드에서 제일 아래 있는 collect 인라인 함수를 사용합니다.
(정확히는 중단+인라인+확장 함수네요. 😅)
이 인라인 함수는 코드에서 알 수 있듯이 내부적으로 FlowCollector 를 생성하여 emit 이 호출 될 때마다 전달 된 action lambda 함수를 호출합니다.
(여기서 action lambda 가 crossinline 으로 마킹 된 이유는 호출하는 쪽에서 action lambda 함수 작성 시 non-local return 을 할 수 없음을 명시적으로 나타내는 것 입니다. 즉, collect 인라인 함수를 보면 내부적으로 생성 한 FlowCollector 객체 안에서 action lambda 함수를 사용하고 있으므로 이 lambda 함수는 블록 내에서 return 를 사용할 수 없습니다.)
위 인라인 함수의 도움으로 우리는 다음과 같이 Flow 를 수집할 수 있습니다.
위 코드에서 보면 flow { } 빌더를 이용하여 Flow 를 생성하고 있습니다. flow { } 빌더는 다음과 같이 정의되어 있습니다.
flow { } 빌더는 파라미터가 없고 반환값도 없는(Unit) supspend lambda 인 block 을 파라미터로 받는데, 이 block 은 이 block 의 호출 컨텍스트는 FlowCollector 입니다. 다시 말해, 이 block 은 FlowCollector 객체를 대상으로 호출 된다는 것입니다. 좀 전에 FlowCollector 코드를 다시 살펴보면 emit() 함수가 하나 정의 된 인터페이스 임을 알 수 있습니다. 그래서 우리는 flow { } 빌더를 이용한 Flow 생성 시 뒤따르는 block 에서 emit() 중단함수를 호출하여 원하는 값을 방출(emit) 할 수 있는 것 입니다.
위 flow 의 생성 및 collect() 중단 함수를 이용한 수집 과정을 그림으로 살펴 봅시다.
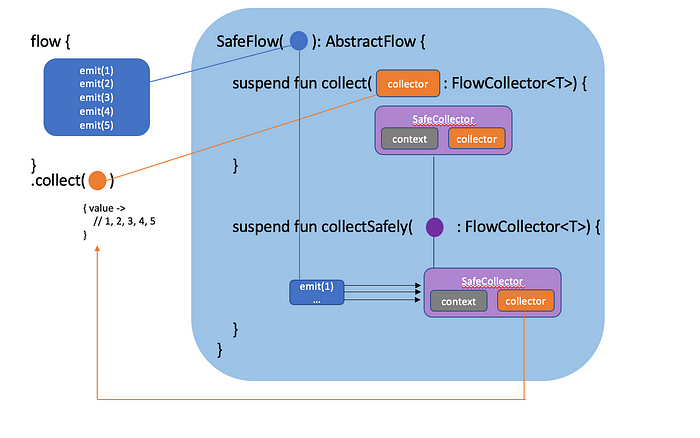
- flow { } 빌더를 이용하여 Flow 를 생성하면서 데이터를 방출하기 위해서 emit(1),…emit(5) 를 수행하는 중단함수 블록을 전달하면
SafeFlow라는 객체가 생성되며, 이 SafeFlow 객체는 위 중단함수 블록을 멤버로 갖게 됩니다. - 이렇게 생성 된 Flow 의 데이터를 수집하기 위해서 collect { value -> … }를 호출하게 되면 앞서 설명했던 것 처럼 수집을 위한 { value -> … } lambda block 은 FlowCollector 형태로 래핑 되고, collect { } 를 호출한 시점의 코루틴 컨텍스트와 FlowCollector 를 멤버로 하는
SafeCollector객체로 다시한번 래핑 됩니다. - 이제 1) 에서 생성한 SafeFlow 에서 데이터를 방출하는 중단함수 블록를 2) 에서 생성한 SafeCollector 를 수신자(Receiver) 로 하여 호출합니다.
3 번을 수행하는 SafeFlow 코드는 다음과 같습니다.
주석의 내용과 같이 SafeFlow 의 멤버 변수인 block 은 1번에서 전달한 데이터를 방출하는 블록이고, collectSafely 함수에 파라미터로 전달 된 collector 는 2번에서 생성된 SafeCollector 입니다.
이렇게 데이터 방출 블록이 실행되면 emit(1),…emit(5) 이 순차적으로 SafeCollector 를 수신자로 하여 호출되고, SafeCollector 는 collect 호출 시 전달 받은 { value -> …} suspend lambda 블록을 멤버로 가지고 있기 때문에 이를 통해 데이터를 전달합니다.
자, 지금까지 살펴본 Flow 의 동작 원리를 간략하게 표현해보면 다음과 같습니다.

Flow 의 생성은 어느 곳에서나 할 수 있지만 collect { }는 중단함수이기 때문에 코루틴에서 호출되어야 합니다. 코루틴에서 Flow.collect { } 를 호출하면 코루틴이 중단(suspend) 되고 Flow.emit(1), Flow.emit(2), Flow.emit(3) 이 호출될 때마다 코루틴이 재개(resumed)되며 동작을 이어 나갑니다.
이제 이 기본적인 Flow 에 조금씩 변경을 가해 봅시다.
먼저, 우리는 Flow 에서 1~5 까지 값을 방출하는 코드가 I/O 가 발생하는 코드라고 가정하고 방출 코드는 적절한 스케쥴러를 통해 워커 스레드에서 동작하게 만들어 보겠습니다.
flow { } 빌더는 기존과 동일하게 1~5 까지 정수를 방출하지만 4번 라인에 보면 flowOn { } 연산자를 이용하여 IO 디스패처를 사용하도록 지정하고 있습니다.
flow 의 경우 flowOn { } 연산자가 사용되면 그것보다 상위 데이터 스트림(업 스트림)의 디스패처를 변경합니다.

이제 우리 Flow 는 위와 같은 모습이 되었습니다. 기존과 차이는 가운데 채널 코루틴이 하나 추가되었습니다. Flow 생성 시점에 flowOn 을 이용하여 Dispatcher 를 변경하도록 지정하면 지정한 Dispatcher 를 컨텍스트 요소로 갖는 채널 코루틴이 생성되고 최종적으로 Flow.collect { } 시 이 채널 코루틴에서 수신 받게 됩니다.
다시말해 Flow.emit(1), Flow.emit(2), Flow.emit(3) 은 Dispatchers.IO 를 컨텍스트 요소로 하는 채널 코루틴에 IO 스케쥴러를 통해 전달되고, 채널 코루틴을 최종적으로 수신하는 FlowCollector 는 별도의 스레드 (Main) 에서 수신중이므로 스레드 전환되어 데이터가 전달 되게 됩니다.
만약 flowOn(CoroutineContext) 에 명시한 코루틴 컨텍스트가 동일하거나, 다른 컨텍스트 요소는 같고 Dispatcher 만 다른 경우 등에 대해서는 내부 최적화가 되어 보다 가볍게 동작합니다.
여기서 방출되는 수 중에서 홀수만 필터하여 사용하도록 다음과 같이 수정되면
Flow 의 흐름은 다음과 같이 그려볼 수 있습니다.

collect() 가 호출되면 flowOn 에 의해 생성 된 ChannelCoroutine 이 정의된 Dispatcher 를 이용해 collect() 를 하기 때문에 FilterCollector 는 해당 Dispatcher 에서 스케쥴링 된 워커 스레드에서 동작하게 되고, Flow emission 역시 마찬가지 입니다. 결과는 다음과 같습니다.
1
3
5이제 이 수만큼 * 로 변환해 볼까요?
변경된 Flow 의 흐름은 다음과 같습니다.
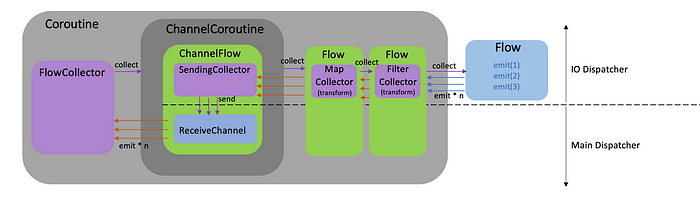
MapCollector 가 추가된 것을 보실 수 있으며, 결과는 다음과 같습니다.
*
***
*****지금까지 Coroutine Flow 의 내부 동작을 간단하게 살펴 보았습니다. Flow 생성시 연산자들이 추가되면 Flow (SafeFlow) 의 형태로 체인을 형성하게 되고 collect() 호출 시 루트 스트림 (최상위 업스트림) 까지 collect() 가 연쇄적으로 호출되어 데이터가 리프 스트림(최하위 다운스트림)까지 전달되게 됩니다.
이 과정에서 collect() 대신 launchIn(CoroutineScope) 를 사용하여 다음과 같이 특정 코루틴 스코프에서 실행하도록 하고, onEach 를 통해 수집할 수도 있습니다만, 이는 현재 스코프에서 새로운 코루틴을 실행하여 Flow 를 구독하는 헬퍼일 뿐 기본적인 내용은 변하지 않습니다.
끝. 😀
