코루틴 디스패쳐 조금 더 살펴보기
Deeper look into coroutine’s dispatchers

앞선 주제들에서 우리는 코루틴 내부에서 중단 함수 및 디스패처가 동작하는 원리에 대해서 알아 보았습니다.
해당 주제들에서 살펴 본 것처럼 우리는 코루틴 프레임워크 사용 시 launch {}, async {} 등의 코루틴 빌더를 통해 코루틴을 생성 및 실행합니다. 이 때, 코루틴이 속한 코루틴 스코프에 어떠한 디스패쳐도 설정되어 있지 않다면 기본적으로 Dispatchers.Default 를 사용하게 됩니다. 만약 Default 디스패쳐를 사용하고 싶지 않다면 Dispatchers 에 1) 사전 정의 된 4가지 Dispatcher 중에 수행하고자 하는 작업에 적합한 것을 선택하거나 2) 직접 디스패쳐를 구현하여 코루틴 빌더의 CoroutineContext 파라미터로 전달하면 됩니다.
(JVM 기준으로 Default, IO, Main, Unconfined 디스패쳐가 사전에 정의 되어 있습니다.)
그렇다면 이렇게 설정한 디스패쳐들은 구체적으로 어떻게 마구 쏟아져 들어오는 코루틴들의 실행을 스케쥴링 할까요? 이번 글에서는 사전 정의 된 디스패쳐들 중에서 Default 와 IO 디스패쳐에 대해 중점적으로 알아보겠습니다.
(Main 디스패쳐는 애플리케이션 메인 스레드(single thread)에서 EventLoop 를 이용해 코루틴의 실행을 스케쥴링하고, Unconfined 는 코루틴(Continuation)이 재개(suspend->resume) 되는 스레드에서 바로 실행하므로 상대적으로 이해가 간단합니다.)
Dispatchers.Default 와 Dispatchers.IO
Kotlin JVM 에는 백그라운드 작업을 수행하기 위해서 Dispatchers.Default 와 Dispatchers.IO 가 준비되어 있으며 작업의 타입에 따라 선택적으로 사용하면 됩니다.
참고 : Kotlin/Native 는 현재 IO 디스패쳐는. 별도로 제공하지 않고 Default 디스패쳐는 싱글 스레드로 동작합니다
일반적으로 우리는 코루틴을 실행할 때 CPU 사용이 주를 이루는 작업은 Dispatchers.Default 를 사용하고, Network, Disk I/O 가 주를 이루는 작업은 Dispatchers.IO 를 사용합니다.
(이러한 작업 구분에 따라 Dispatchers.Default 와 IO 를 선택하는 것에 대해서 반론을 제기하는 아티클도 있는데 해당 아티클에서는 코루틴 문서가 정확치 않은 상황에서 RX Schedulers 의 사용에 영향을 받은 개발자들이 유추하여 이런 선택을 한 것이라는 주장과 현재 코루틴 디스패쳐는 그 자체적으로 문제가 있다는 주장을 합니다. 문제가 있는 부분에 대해서는 Jetbrains 에서도 내부 개선 계획이 있는 것 같으니 지켜보면 될 것 같습니다. 😅)
코루틴 JVM 에서 Dispatchers 의 내부 구현을 살펴보면 Dispatchers.Default 와 Dispatchers.IO 는 CoroutineScheduler 라는 동일한 스케쥴러를 공유합니다.
코루틴들은 디스패쳐를 통해 CoroutineScheduler 로 요청 될 때 Task 라는 형태로 래핑되어 요청됩니다. 이 때, Dispatchers.Default 디스패쳐를 사용하도록 설정 된 코루틴은 NonBlockingContext 으로 표시되어 내부적으로 CPU intensive 한 작업들을 위한 큐를 이용하여 처리되고, Dispatchers.IO 디스패쳐를 사용하도록 설정 된 코루틴은 Task 에 ProbablyBlockingContext 로 표시되어 내부적으로 I/O intensive 한 작업들을 위한 큐를 이용하여 처리 됩니다.
이들의 관계를 그려보면 다음처럼 그려볼 수 있을 것 같습니다.
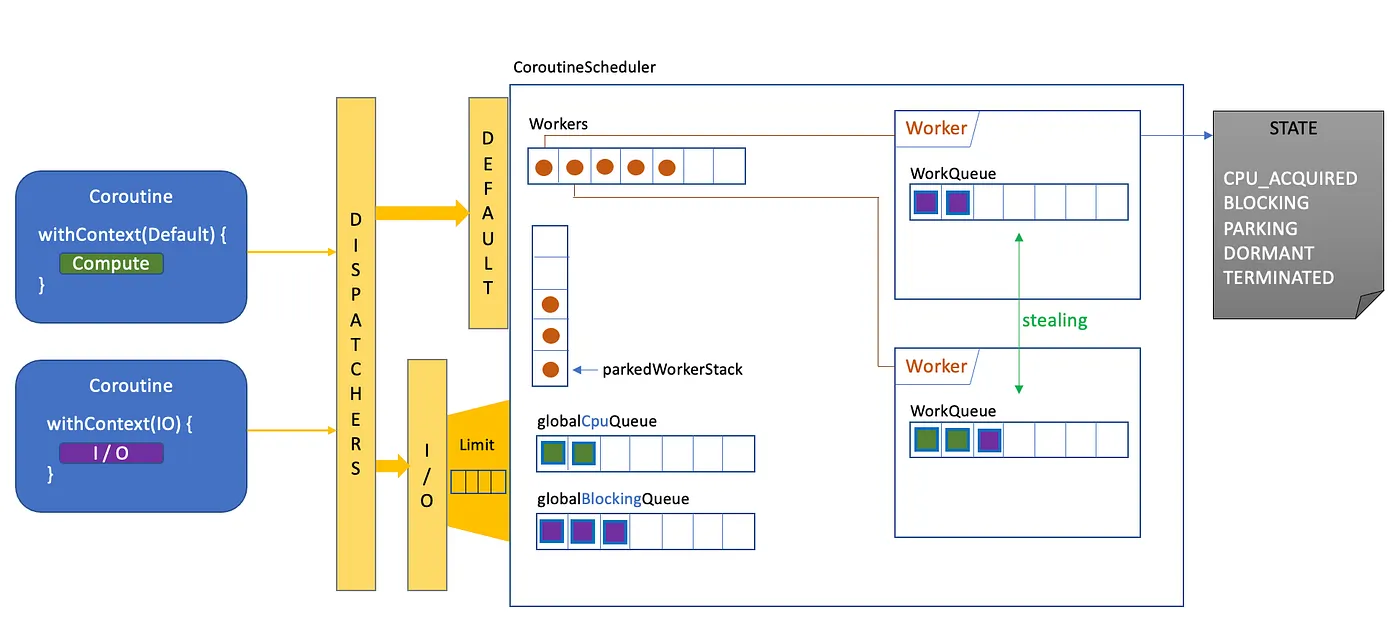
다소 엉성한 그림에 양해를 구합니다. 😅
그러면 먼저 그림의 왼쪽부터 살펴 보겠습니다.
우리는 상대적으로 CPU 연산이 주를 이루는 코루틴(초록색 코드 블럭을 갖는)과 I/O 작업이 주를 이루는 코루틴(보라색 코드 블럭을 갖는)을 요청하고자 합니다.
이 때, 우리는 코루틴이 사용할 디스패쳐로 각각 Dispatcher.Default 와 Dispatchers.IO 를 설정해 주게 됩니다.
Default 디스패쳐의 경우 바로 CoroutineScheduler 에 수행하고자 하는 작업을 Task 형식으로 래핑하여 스케쥴링을 요청하게 되고, IO 디스패쳐의 경우 LimitingDispatcher 라는 클래스로 래핑되어 자체적으로 설정 된 병렬 실행 수 제한치(parallelism limit)에 따라 실제 CoroutineScheduler 로 스케쥴링 요청을 할 지, 아니면 자체적으로 갖는 작업 큐에 작업을 대시 시킬지 결정하게 됩니다. 즉, I/O Task 의 동시 수행 수는 이 LimitingDispatcher 를 통해 조절 됩니다.
자, 이제 CoroutineScheduler (파란색 사각 영역) 로 들어가 봅시다.
앞서 외부에서 요청 된 작업(코루틴)들은 Task 라는 단위로 래핑 되어 CoroutineScheduler 에서 스케쥴링 된다고 하였습니다. Task 는 다음과 같이 정의되어 있으며 내부적으로 TaskContext 를 갖습니다.
위 정의에서 Task 구현체 인 TaskImpl 을 보면 수행 할 코드 블럭(block)과 CoroutineScheduler 에 요청 된 시간(sumissionTime) 그리고 taskContext 로 이루어져 있습니다.
TaskContext 는 taskMode(TASK_NON_BLOCKING | TASK_PROBABLY_BLOCKING) 와 afterTask 함수로 이루어 지는데
- Default 디스패쳐를 사용했다면 TASK_NON_BLOCKING 으로 마킹되고
- IO 디스패쳐를 사용했다면 TASK_PROBABLY_BLOCKING 으로 마킹됩니다.
afterTask() 함수는 TaskContext 가 NON_BLOCKING 인 경우 별도로 처리할 동작이 없어 비어있으며, PROBABLY_BLOCKING 인 경우 앞서 설명한 것처럼 LimitingDispatcher 에서 자체적으로 I/O parallelism 컨트롤을 위해 자체 큐를 운용하고 있으므로 이 함수가 불릴 때 자체 큐에서 대기 중인 작업을 CoroutineScheduler 에 추가 공급하는데 쓰이게 됩니다.
이런식으로 수행해야 할 작업들은 Task 라는 단위로 CoroutineScheduler 에서 관리되며 내부 Worker 들에 의해 실행됩니다. CoroutineScheduler 는 Java.Executor 의 구현체이며 그래서 일반적으로 Excutor 가 갖는 다음과 같은 속성 또한 갖습니다.
- corePoolSize : 최소로 유지되는 Worker 수
- maxPoolSize : 최대 Worker 수
- idleWorkerKeepAliveNs : 지정된 나노 초가 지난 유휴 Worker 는 제거
이러한 속성에 따라서 CoroutineScheduler 는 필요한 만큼의 Worker 를 생성/추가/제거 하며 생성된 Worker 들은 배열로 관리합니다. 이렇게 관리되는 Worker 들 중에서 Parked Worker 들은 추가적으로 별도의 스택에서 참조하여 관리합니다.
(위 이미지에서 parkedWorkerStack)
잠깐❗️ 갑자기 Parked Worker 는 무엇일까요?
CoroutineScheduler 에서 Worker 는 우선 Java Thread 입니다. JVM Thread 는 생명 주기 동안 다음과 같은 상태를 갖을 수 있고 Worker 또한 Thread 이므로 동일합니다.

Thread 는 새로 생성(NEW) 되어 실행(RUNNABLE) 되는 동안 여러가지 이유로 대기 상태로 들어갈 수 있는데, 대표적인 예로 Lock 획득을 위한 대기(BLOCKED)와 특정 이벤트가 발생할 때까지 대기하기 위한 Object.wait(), LockSupport.park() 등의 호출로 인한 대기(WAITING | TIMED_WAITING) 를 들 수 있습니다.
여기서 우리가 눈여겨 보아야 할 부분은 형광색을 칠한 LockSupport.park() 그 중에서도 parkNano() 입니다. CoroutineScheduler 에서 운용되는 Worker 는 수행해야 할Task 들(❓)을 완료하고 나면 LockSupport.parkNanos() 를 이용하여 TIMED_WAITING 상태로 진입하고 위에서 언급한 parkedWorkerStack 에 Push 되어 대기합니다. 그러면 그 이후 또 다른 Task 들의 스케쥴링이 요청 될 때 모든 활성 Worker 들이 바빠서 요청 된 Task 를 수행할 수 없으면 parkedWorkerStack 에서 대기중인 Worker 를 깨워 Task 를 수행하도록 합니다. 여기서 대기중인 Worker 들을 LIFO 타입 인 Stack 형식으로 관리하는 이유는 최근까지 사용되던 Worker 를 재사용하는 것이 Memory footprint 감소와 Reference locality 면에서 이득이 있기 때문입니다. parkedWorkerStack은 묘사하자면 일을 마친 택시들의 주차장이라고 할 수 있겠네요. 😃
위 설명 중 “Worker 는 수행해야 할 Task 들” 이라고 Task 에 복수 표현을 사용하였습니다. 처음 제시했던 이미지를 다시 살펴보면 Worker 내부에 큐가 있는 것을 알 수 있습니다. Worker 는 내부적으로 WorkQueue 라는 별도의 작업 큐를 가지고 있으며, 이 큐는 SPMC (Single-Producer, Multi-Consumer) 자료구조로 사용 됩니다.
Producer 는 해당 큐를 소유한 Worker 로 유일한 Task Producer 입니다. Multi-Consumer 인 이유는 어떤 Worker 가 너무 바빠서 대기중인 Task 가 너무 많거나 혹은 어떤 Worker 가 Blocking I/O 로 인해 대기 상태에 들어가 요청된 Task 들의 수행이 지연되고 있다면 일을 먼저 마친 Worker 가 주차장(😄)으로 가기 전에 바쁜 Worker 를 살펴본 후 해당 Worker 의 Task 를 뺏어다 대신 수행하는 Task Stealing Algorithm 이 적용 되어 있기 때문입니다. 다시말해 Worker 내부의 로컬 큐는 Worker 자신도 Consumer 로써 접근하지만 Task Stealing 을 수행하고자 하는 다른 Worker 도 Consumer 로써 접근 가능하여 Multi-Consumer 를 사용합니다.
이러한 SPMC 구조는 ForkJoinPool 에서도 볼 수 있는데 해당 경우와 동일한 이점이 있습니다. Worker 는 Task 를 로컬 큐로 가져온 후에는 Lock-Free 로 동작 할 수 있기 때문에 더 나은 성능과 안정성을 챙길 수 있습니다. 또한 특정 타입의 Task 를 수행하는 Worker 의 경우 해당 Worker 가 수행할 경우 더 효율적인 Task 를 Stealing 하도록 구현할 수도 있습니다. CoroutineScheduler 에서도 CPU bound task 를 수행하던 Worker 는 cpuPermit 이란 것을 획득하고 CPU bound task 를 우선 수행합니다.
최초 제시한 이미지 좌측 하단을 호변 globalCpuQueue 와 globalBlockingQueue 가 있습니다. 각 Worker 에 할당되지 못한 (타입이 맞지 않는 등의 이유로) Task 들은 이곳에 TaskContext 에 따라 적절한 큐에 삽입된 이후 가용한 Worker 가 생기면 자신의 로컬큐로 가져가 이후 작업을 수행합니다.
이러한 방식으로 JVM 에서 코루틴들은 스캐쥴링 되고 있습니다.
오늘도 행복한 하루 되세요. 👍
끝.
